In retail, competition is fierce, and in its ever-evolving landscape, consumer expectations are higher than ever.
For years, our AI-driven solutions have been the foundation that empowers businesses to sharpen their competitive pricing and optimize digital shelf performance. But in today’s world, evolution is constant—so is innovation. We now find ourselves at the frontier of a new era in AI. With the dawn of Generative AI and the rise of Large Language Models (LLMs), the possibilities for eCommerce companies are expanding at an unprecedented pace.
These technologies aren’t just a step forward; they’re a leap—propelling our capabilities to new heights. The insights are deeper, the recommendations more precise, and the competitive and market intelligence we provide is sharper than ever. This synergy between our legacy of AI expertise and the advancements of today positions DataWeave to deliver even greater value, thus helping businesses thrive in a fast-paced, data-driven world.
This article marks the beginning of a series where we will take you through these transformative AI capabilities, each designed to give retailers and brands a competitive edge.
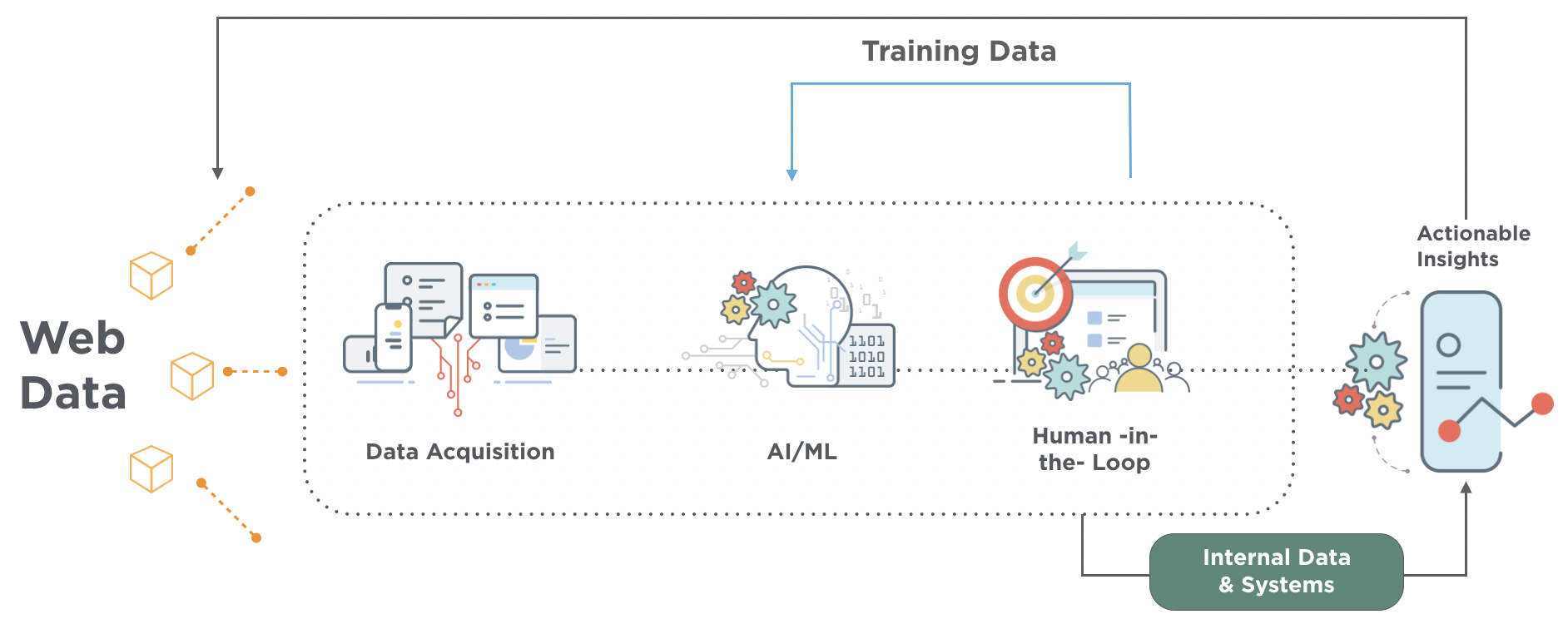
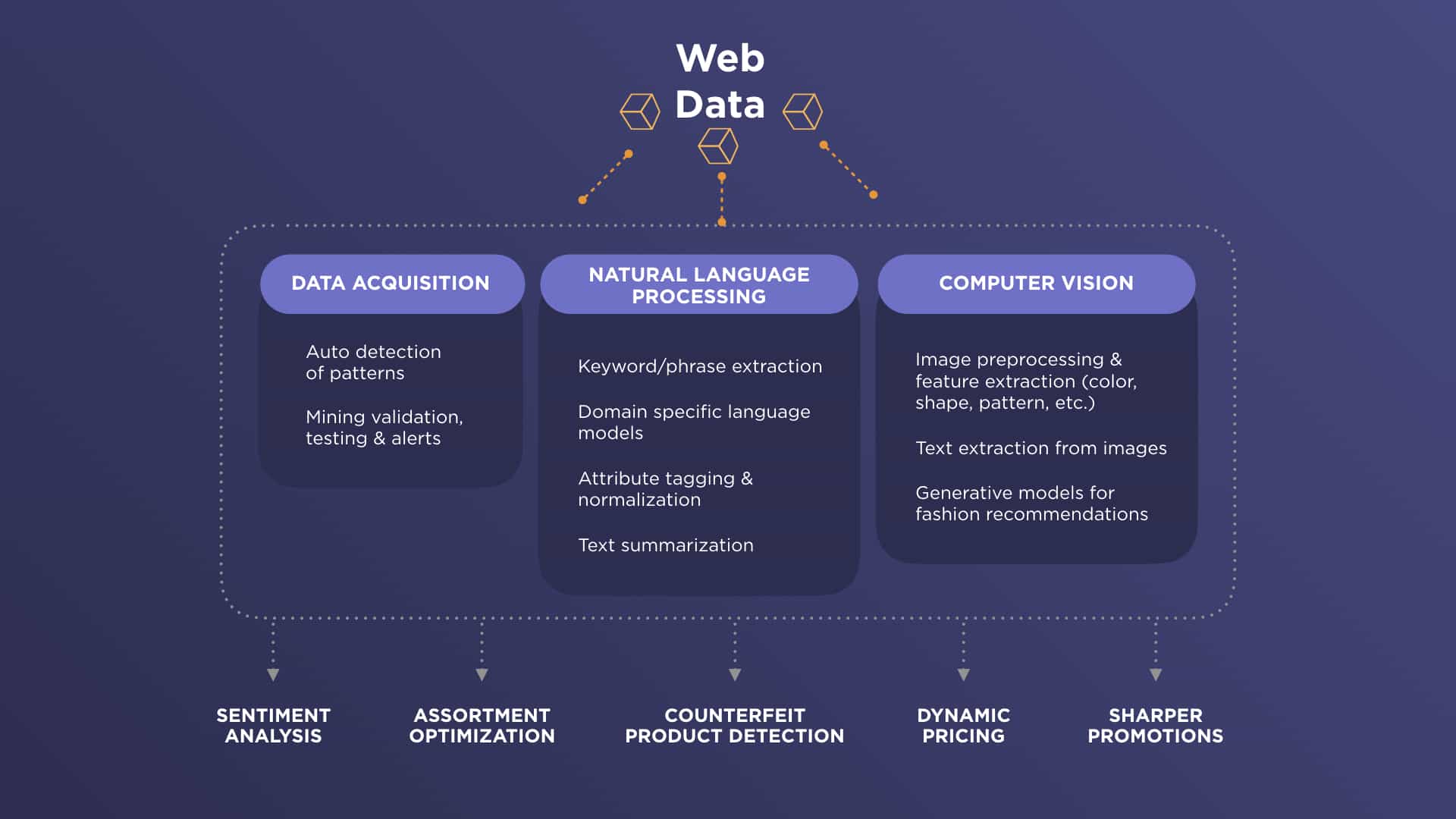
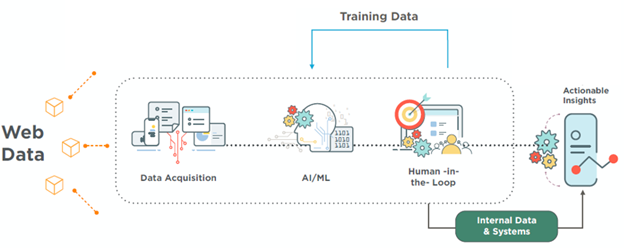
In this first piece, we’ll offer a snapshot of how DataWeave aggregates and analyzes billions of publicly available data points to help businesses stay agile, informed, and ahead of the curve. These fall into four broad categories:
- Product Matching
- Attribute Tagging
- Content Analysis
- Promo Banner Analysis
- Other Specialized Use Cases
Product Matching
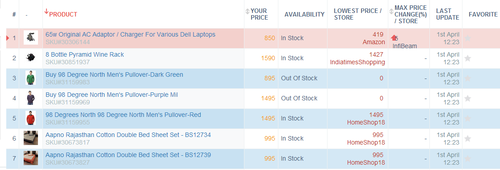
Dynamic pricing is an indispensable tool for eCommerce stores to remain competitive. A blessing—and a curse—of online shopping is that users can compare prices of similar products in a few clicks, with most shoppers gravitating toward the lowest price. Consequently, retailers can lose sales over minor discrepancies of $1–2 or even less.
All major eCommerce platforms compare product prices—especially their top selling products—across competing players and adjust prices to match or undercut competitors. A typical product undergoes 20.4 price changes annually, or roughly once every 18 days. Amazon takes it to the extreme, changing prices approximately every 10 minutes. It helps them maintain a healthy price perception among their consumers.
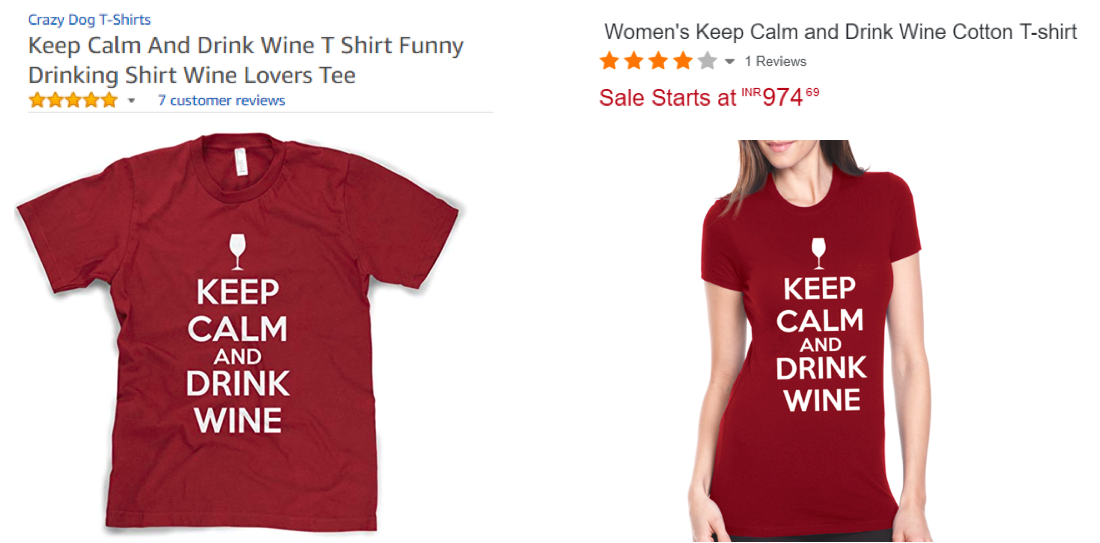
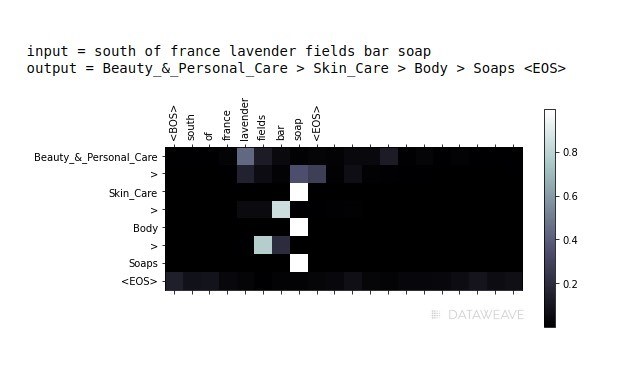
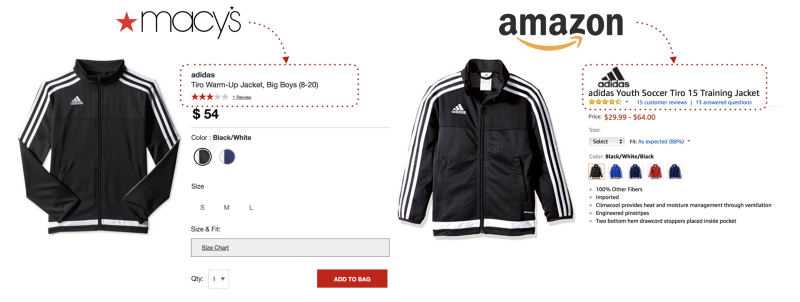
However, accurate product matching at scale is a prerequisite for the above, and that poses significant challenges. There is no standardized approach to product cataloging, so even identical products bear different product titles, descriptions, and attributes. Information is often incomplete, noisy, or ambiguous. Image data contains even more variability—the same product can be styled using different backgrounds, lighting, orientations, and quality; images can have multiple overlapping objects of interest or extraneous objects, and at times the images and the text on a single page might belong to completely different products!
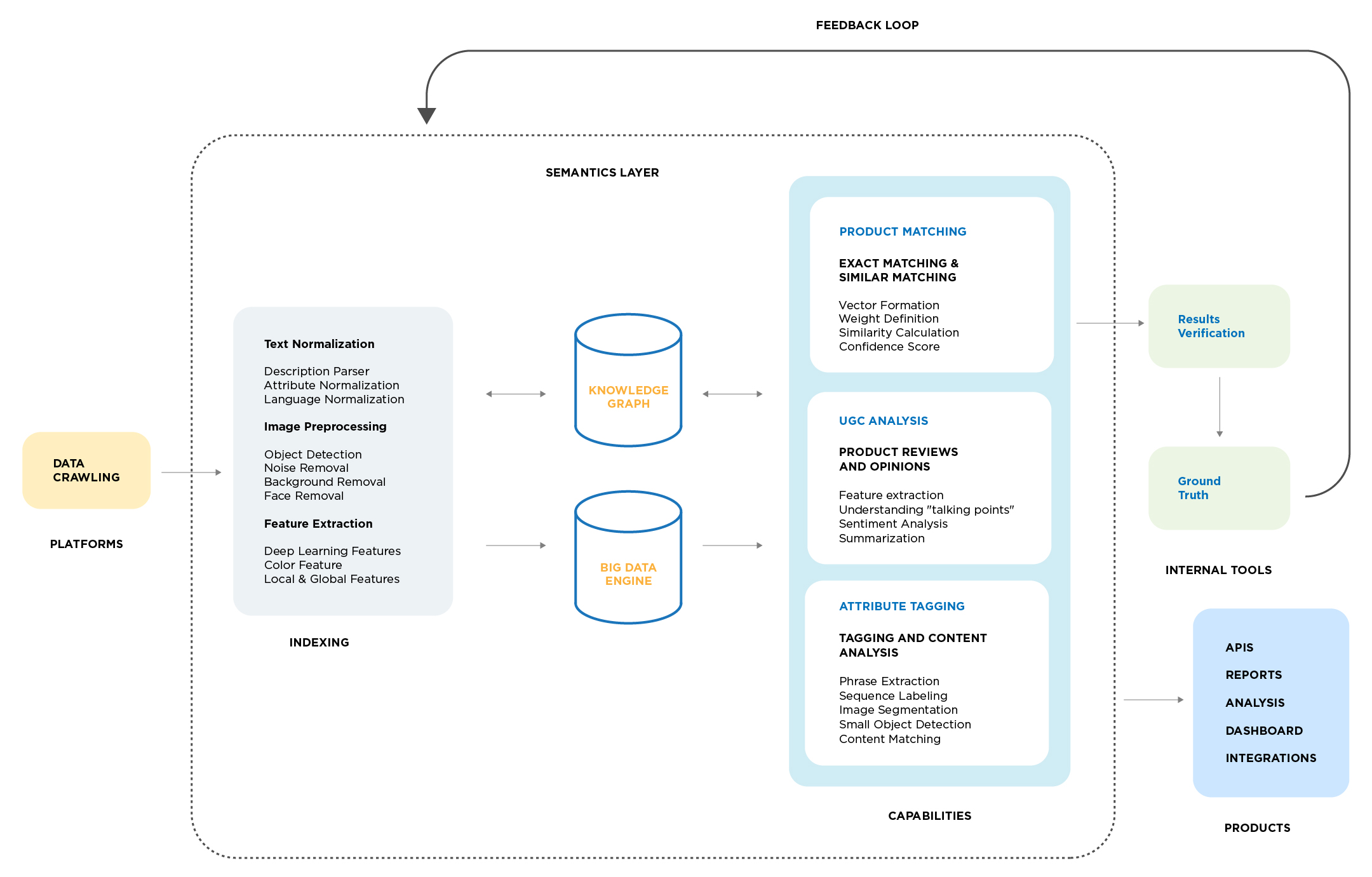
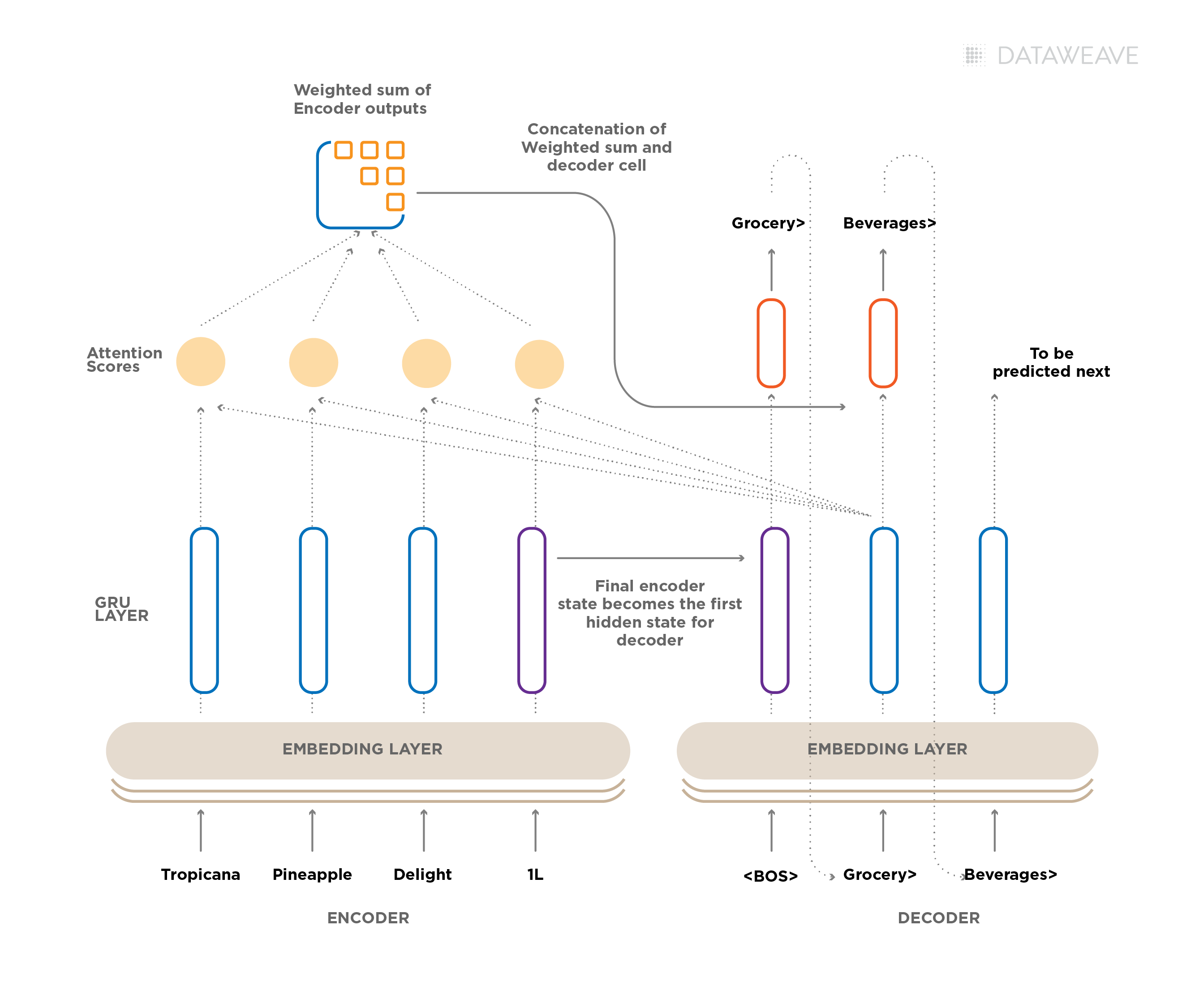
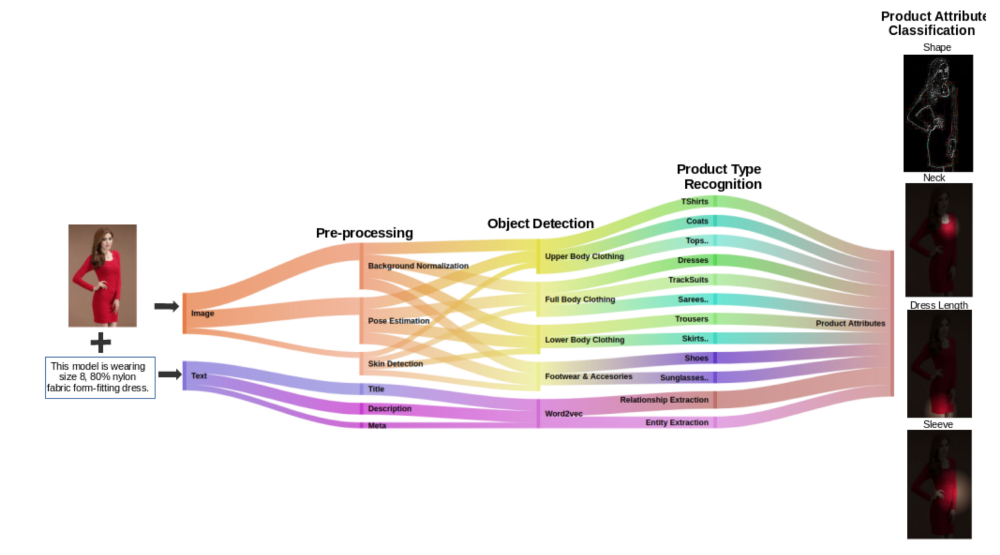
DataWeave leverages advanced technologies, including computer vision, natural language processing (NLP), and deep learning, to achieve highly accurate product matching. Our pricing intelligence solution accurately matches products across hundreds of websites and automatically tracks competitor pricing data.
Here’s how it works:
Text Preprocessing
It identifies relevant text features essential for accurate comparison.
- Metadata Parsing: Extracts product titles, descriptions, attributes (e.g., color, size), and other structured data elements from Product Description Pages (PDP) that can help in accurately identifying and classifying products.
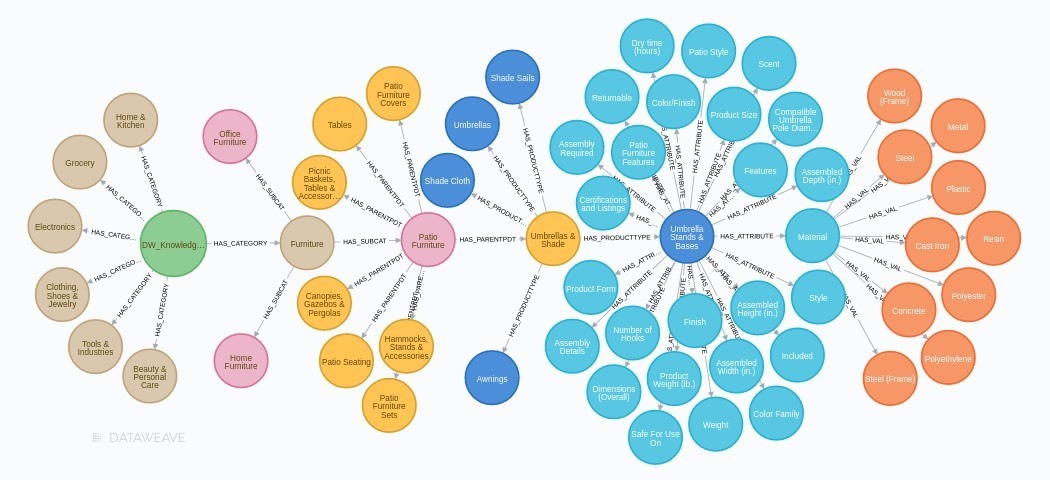
- Attribute-Value Normalization: Normalize attributes names (e.g. RAM vs Memory) and their values (e.g., 16 giga bytes vs 16 gigs vs 16 GB); brand names (e.g., Benetton vs UCB vs United Colors of Benetton); mapping category hierarchies a standard taxonomy.
- Noise Removal: Removes stop words and other elements with no descriptive value; this focuses keyword extraction on meaningful terms that contribute to product identification.
Image Preprocessing
Image processing algorithms use feature extraction to define visual attributes. For example, when comparing images of a red T-shirt, the algorithm might extract features such as “crew neck,” “red,” or “striped.”

Image hashing techniques create a unique representation (or “hash”) of an image, allowing for efficient comparison and matching of product images. This process transforms an image into a concise string or sequence of numbers that captures its essential features even if the image has been resized, rotated, or edited.
Before we perform these activities there is a need to preprocess images to prepare them for downstream operations. These include object detection to identify objects of interest, background removal, face/skin detection and removal, pose estimation and correction, and so forth.
Embeddings
We have built a hybrid or a multimodal product-matching engine that uses image features, text features, and domain heuristics. For every product we process we create and store multiple text and image embeddings in a vector database. These include a combination of basic feature vectors (e.g. tf-idf based, colour histograms, share vectors) to more advanced deep learning algorithms-based embeddings (e.g., BERT, CLIP) to the latest LLM-based embeddings.
Classification
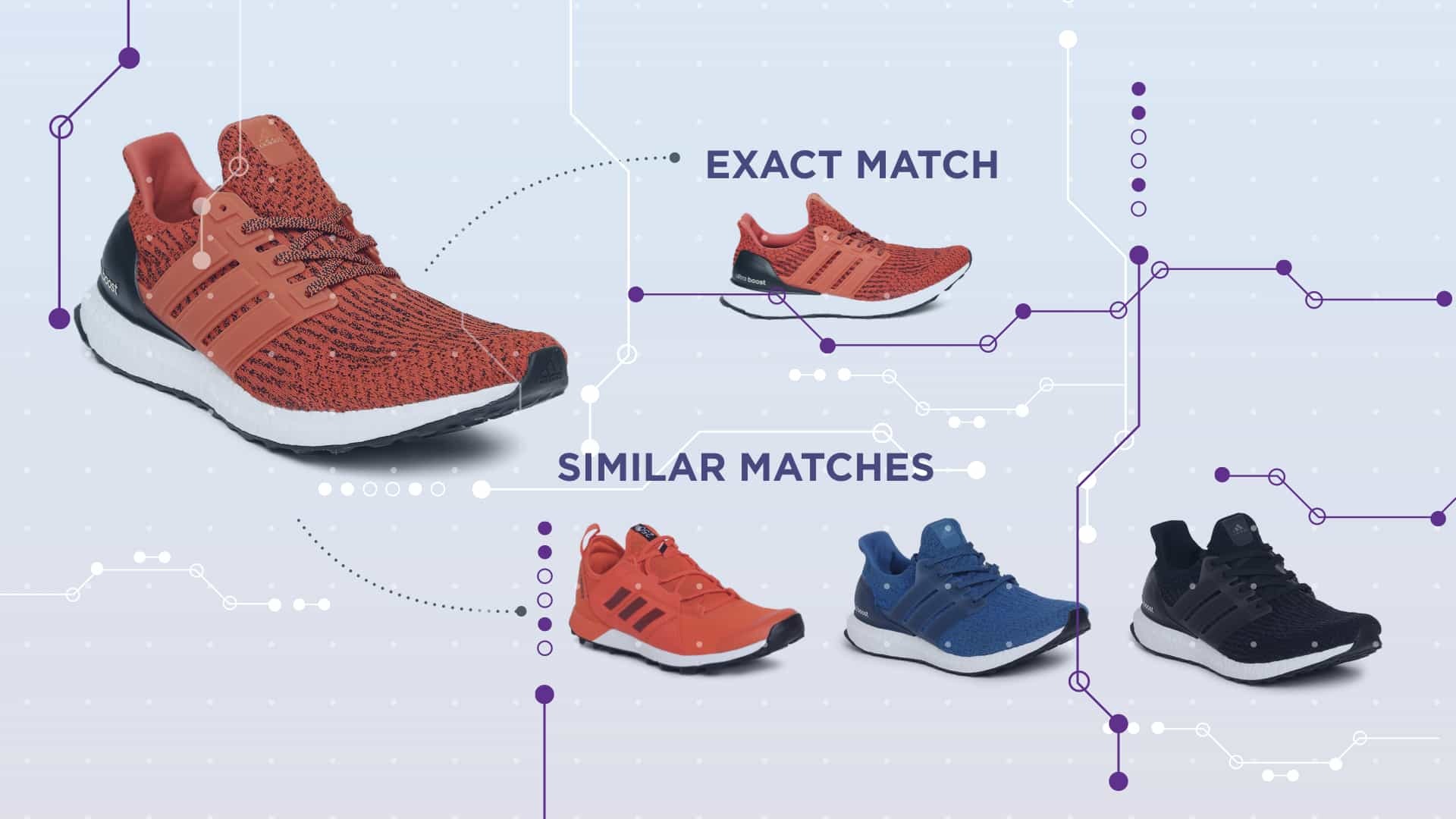
Classification algorithms enhance product attribute tagging by designating match types. For example, the product might be identified as an “exact match”, “variant”, “similar”, or “substitute.” The algorithm can also identify identical product combinations or “baskets” of items typically purchased together.
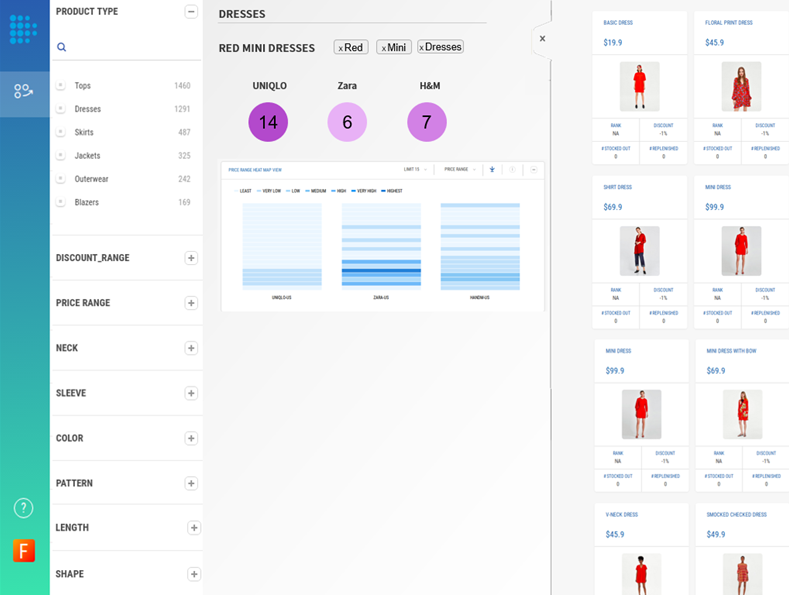
What is the Business Impact of Product Matching?
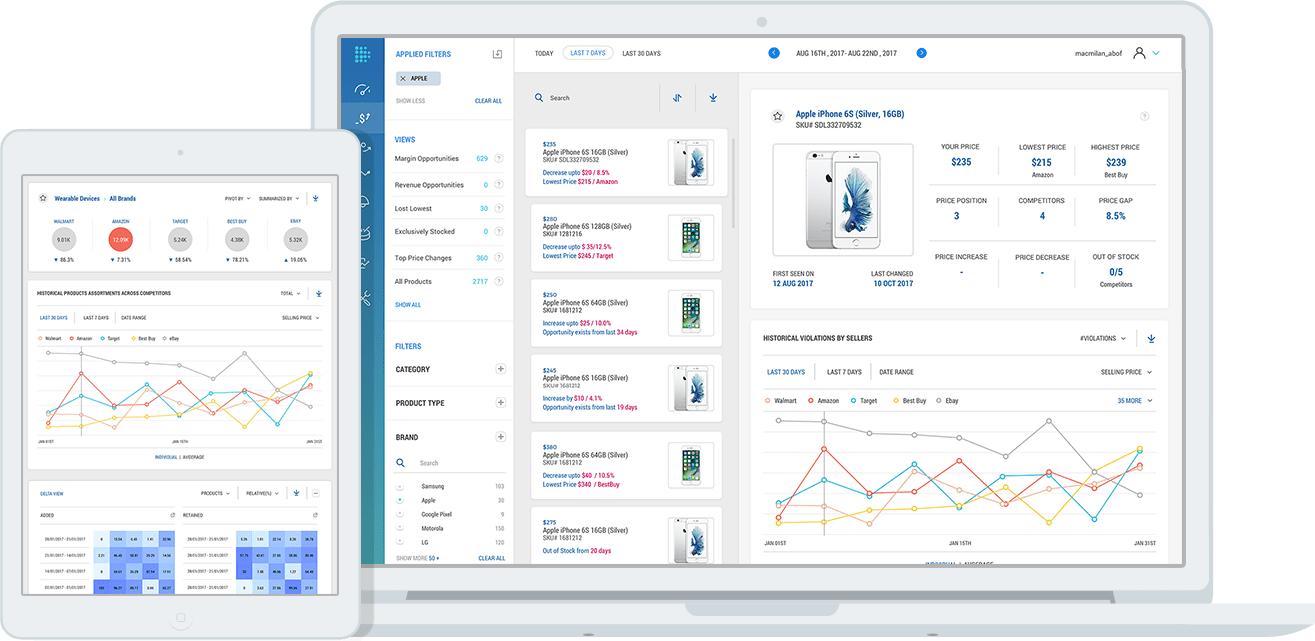
- Pricing Intelligence: Businesses can strategically adjust pricing to remain competitive while maintaining profitability. High-accuracy price comparisons help businesses analyze their competitive price position, identify opportunities to improve pricing, and reclaim market share from competitors.
- Similarity-Based Matching: Products are matched based on a range of similarity features, such as product type, color, price range, specific features, etc., leading to more accurate matches.
- Counterfeit Detection: Businesses can identify counterfeit or unauthorized versions of branded products by comparing them against authentic product listings. This helps safeguard brand identity and enables brands to take legal action against counterfeiters.
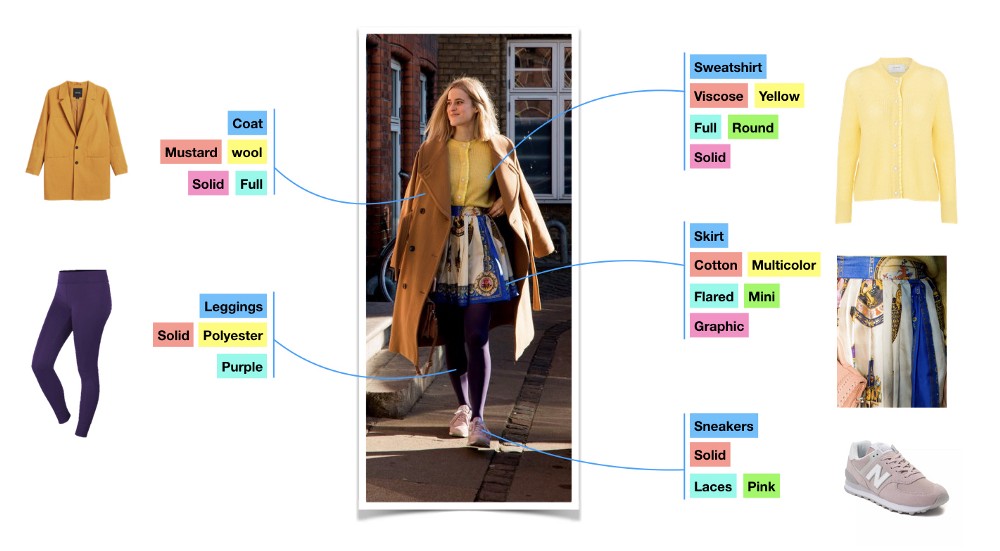
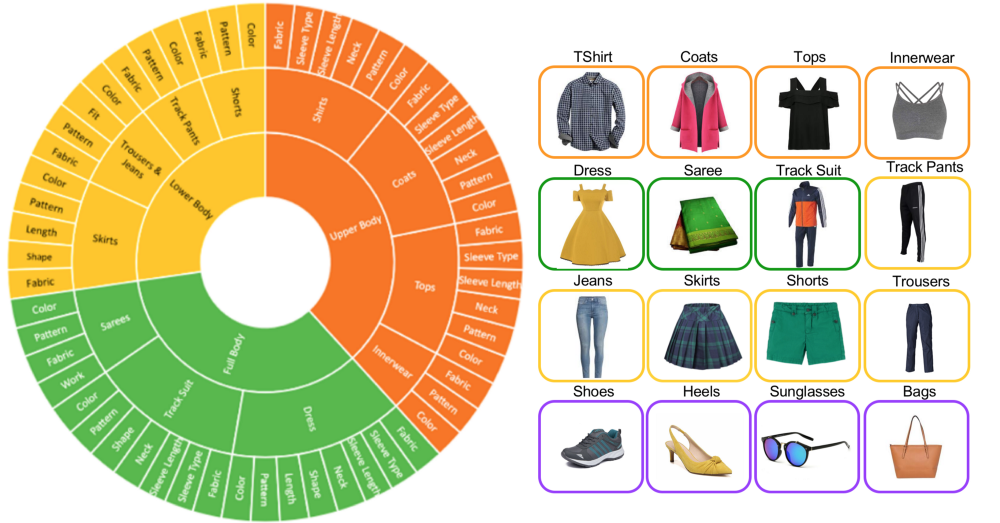
Attribute Tagging
Attribute tagging involves assigning standardized tags for product attributes, such as brand, model, size, color, or material. These naming conventions form the basis for accurate product matching. Tagging detailed attributes, such as specifications, features, and dimensions, helps match products that meet similar criteria. For example, tags like “collar” or “pockets” for apparel ensure high-fidelity product matches for hard-to-distinguish items with minor stylistic variations.

Including tags for synonyms, variants, and long-tail keywords (e.g., “denim” and “jeans”) improves the matching process by recognizing different terms used for similar products. Metadata tags categorize similar items according to SKU numbers, manufacturer details, and other identifiers.
Altogether, these capabilities provide high-quality product matches and valuable metadata for retailers to classify their products and compare their product assortment to competitors.
User-Generated Content (UGC) Analysis
Customer reviews and ratings are rich sources of information, enabling brands to gauge consumer sentiment and identify shortcomings regarding product quality or service delivery. However, while informative, reviews constitute unstructured “noisy” data that is actionable only if parsed correctly.
Here’s where DataWeave’s UGC analysis capability steps in.
- Feature Extractor: Automatically pulls specific product attributes mentioned in the review (e.g., “battery life,” “design” and “comfort”)
- Feature Opinion Pair: Pairs each product attribute with a corresponding sentiment from the review (e.g., “battery life” is “excellent,” “design” is “modern,” and “comfort” is “poor”)
- Calculate Sentiment: Calculates an overall sentiment score for each product attribute

The final output combines the information extracted from each of these features, which looks something like this:
- Battery life is excellent
- Design is modern
- Not satisfied with the comfort
The algorithm also recognizes spammy reviews and distinguishes subjective reviews (i.e., those fueled by emotion) from objective ones.

Promo Banner Analysis
Our image processing tool can interpret promotional banners and extract information regarding product highlights, discounts, and special offers. This provides insights into pricing strategies and promotional tactics used by other online stores.
For example, if a competitor offers a 20% discount on a popular product, you can match or exceed this discount to attract more customers.
The banner reader identifies successful promotional trends and patterns from competitors, such as the timing of discounts, frequently promoted product categories or brands, and the duration of sales events. Ecommerce stores can use this information to optimize their promotion strategies, ensuring they launch compelling and timely offers.
Other Specialized Use Cases
While these generalized AI tools are highly useful in various industries, we’ve created other category—and attribute-specific capabilities for specialty goods (e.g., those requiring certifications or approval by federal agencies) and food items. These use cases help our customers adhere to compliance requirements.
Certification Mark Detector
This detector lets retailers match items based on official certification marks. These marks represent compliance with industry standards, safety regulations, and quality benchmarks.
Example:
- USDA Organic: Certification for organic food production and handling
- ISO 9001: Quality Management System Certification
By detecting these certification marks, the system can accurately match products with their certified counterparts. By identifying which competitor products are certified, retailers can identify products that may benefit from certification.

Nutrition Fact Table Reader
Product attributes alone are insufficient for comparing food items. Differences in nutrition content can influence product category (e.g., “health food” versus regular food items), price point, and consumer choice. DataWeave’s nutrition fact table reader scans nutrition information on packaging, capturing details such as calorie count, macronutrient distribution (proteins, fats, carbohydrates), vitamins, and minerals.
The solution ensures items with similar nutritional profiles are correctly identified and grouped based on specific dietary requirements or preferences. This helps with price comparisons and enables eCommerce stores to maintain a reliable database of product information and build trust among health-conscious consumers.

Building Next-Generation Competitive and Market Intelligence
Moving forward, breakthroughs in generative AI and LLMs have fueled substantial innovation, which has enabled us to introduce powerful new capabilities for our customers.

These include:
- Building Enhanced Products, Solutions, and Capabilities: Generative AI and LLMs can significantly elevate the performance of existing solutions by improving the accuracy, relevance, and depth of insights. By leveraging these advanced AI technologies, DataWeave can enhance its product offerings, such as pricing intelligence, product matching, and sentiment analysis. These tools will become more intuitive, allowing for real-time updates and deeper contextual understanding. Additionally, AI can help create entirely new solutions tailored to specific use cases, such as automating competitive analysis or identifying emerging market trends. This positions DataWeave to remain at the forefront of innovation, offering cutting-edge solutions that meet the evolving needs of retailers and brands.
- Reducing Turnaround Time (TAT) to Go-to-Market Faster: Generative AI and LLMs streamline data processing and analysis workflows, enabling faster decision-making. By automating tasks like data aggregation, sentiment analysis, and report generation, AI dramatically reduces the time required to derive actionable insights. This efficiency means that businesses can respond to market changes more swiftly, adjusting pricing or promotional strategies in near real-time. Faster insights translate into reduced turnaround times for product development, testing, and launch cycles, allowing DataWeave to bring new solutions to market quickly and give clients a competitive advantage.
- Improving Data Quality to Achieve Higher Performance Metrics: AI-driven technologies are exceptionally skilled at cleaning, organizing, and structuring large datasets. Generative AI and LLMs can refine the data input process, reducing errors and ensuring more accurate, high-quality data across all touchpoints. Improved data quality enhances the precision of insights drawn from it, leading to higher performance metrics like better product matching, more accurate price comparisons, and more effective consumer sentiment analysis. With higher-quality data, businesses can make smarter, more informed decisions, resulting in improved revenue, market share, and customer satisfaction.
- Augmenting Human Bandwidth with AI to Enhance Productivity: Generative AI and LLMs serve as powerful tools that augment human capabilities by automating routine, time-consuming tasks such as data entry, classification, and preliminary analysis. This allows human teams to focus on more strategic, high-value activities like interpreting insights, building relationships with clients, and developing new business strategies. By offloading these repetitive tasks to AI, human productivity is significantly enhanced. Employees can achieve more in less time, increasing overall efficiency and enabling teams to scale their operations without needing a proportional increase in human resources.
In our ongoing series, we will dive deep into each of these capabilities, exploring how DataWeave leverages cutting-edge AI technologies like Generative AI and LLMs to solve complex challenges for retailers and brands.
In the meantime, talk to us to learn more!